Halo,Elasticsearch
Elasticsearch
版本为7.10.1
Elasticsearch是Elastic Stack核心的分布式搜索和分析引擎,简称ES。Elasticsearch为所有类型的数据提供近乎实时的搜索和分析。无论您是结构化文本还是非结构化文本,数字数据或地理空间数据,Elasticsearch都能以支持快速搜索的方式有效地对其进行存储和索引。您不仅可以进行简单的数据检索,还可以聚合信息来发现数据中的趋势和模式。随着数据和查询量的增长,Elasticsearch的分布式特性使您的部署可以顺畅地无缝增长。
核心概念
Elasticsearch不会将信息存储为列数据的行,而是存储已序列化为JSON文档的复杂数据结构。当集群中有多个Elasticsearch节点时,存储的文档将分布在集群中,并且可以从任何节点立即访问。
Elasticsearch是面向文档的,关系行数据库和Elasticsearch客观的对比! 一切都是json
| 关系数据库 | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(table) | 类型(types)(7版本以及之后会被抛弃,默认_doc) |
| 行(row) | 文档(documents) |
| 字段(column) | 字段(indices.settings.mapping.properties,fields) |
索引与文档
Elasticsearch不会将信息存储为列数据的行,而是存储已序列化为JSON文档的复杂数据结构。
7版本之后,可以理解成已经把表的概念抛弃,现可看作索引(indices)即是库也是表,索引包含了字段的映射信息,是文档的优化集合,而文档(document)相当于行,是字段的集合,这些字段是包含数据的键值对。一般情况下定义索引(indices)的时候需要指定字段类型信息(映射信息),Elasticsearch提供了无模式的功能,即”猜“,无需显式指定如何处理文档中可能出现的每个不同字段即可对文档建立索引,但是还是建议自行创建或者定义相关规则。
-
binary 二进制编码为Base64字符串 一般用于大字段类型,如图片、文档等
-
boolean true/false
-
number 数字类型
-
text 分析的非结构化文本 一般用于全文检索,不用于排序,很少用于聚合
-
date 日期类型 JSON中是没有日期类型的,所以ES中一般是格式化的字符串,长整型等
其他的Elasticsearch的数据类型详见Fields data type
搜索与分析
Elasticsearch可以用于文档的存储、检索文档及其元数据,但是其真正强大的是封装了基于Apache Lucene搜索引擎库构建的全套搜索功能。
Elasticsearch支持结构化查询,全文查询和结合了两者的复杂查询,可以像传统数据一样根据关键字name='张三'或者age=20,进行查询,而全文检索则会找到所有与查询字符串匹配的文档,并按相关性对它们进行归还(搜索词的匹配程度分数)。Elasticsearch提供了一整套多语言的REST API客户端包供使用,包括Java,JavaScript,Go,.NET,PHP,Perl,Python或Ruby。各语言客户端传送门。而且在7版本之后,Elasticsearch已经实现了SQL功能,SO,你可以写像传统数据库一样写SQL查询数据。当然SQL也是支持在REST API中的。SQL Access传送门
而且,ES有强大的数据分析功能,可以快速分析出你想要的数据。
集群 、节点与分片
每一个节点代表的是一个Elasticsearch服务实例,而集群就是由一个或多个的一样的cluster.name的配置节点组成,Elasticsearch会自动在所有节点之间分配数据与查询负载,任何节点都可成为主节点或副节点,而多节点的情况下,主节点只会调度副节点,不需要涉及到文档级别的变更和搜索等操作。
保存数据的时候,需要用到索引(indices),索引实际上是指向一个或者多个物理 分片 的 逻辑命名空间 。创建索引时,Elasticsearch会默认的给索引分配5个主分片number_of_shards与1个每个主分片的副分片number_of_replicas。
//修改分片数
PUT /blogs
{
"settings" : {
"number_of_shards" : 5,
"number_of_replicas" : 1
}
}
一个分片是一个底层的工作单元,它仅仅保存了全部数据中的一部分,每一个分片是一个Lucene的实例,自己本身就是一个完整的搜索引擎。Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
倒排索引
比如,我们在Google中搜索”年轻人你不讲武德,我劝你耗子尾汁“,则出现了以下的匹配内容。
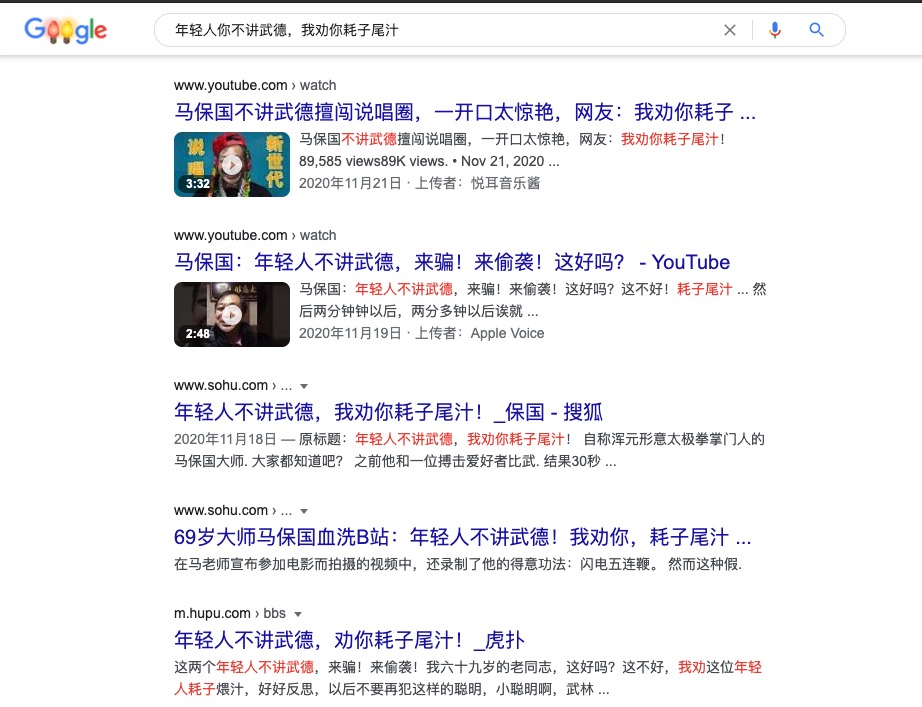
如果,让你自己去设计一个搜索引擎你会怎么去做?
最容易想到的办法就是关键字匹配了,搜索的内容中匹配的关键字越多则相关度也越大。那一个语句又怎么进行关键字匹配呢?
答案是▼
分词
主要的目的是将句子分割成短语或关键字。去停用词指的是去除和查询不想管的内容,比如标点符号
比如,”年轻人你不讲武德,我劝你耗子尾汁“,去停用词可以得到词汇有
年轻人、不讲武德、武德、我劝你、耗子尾汁等等等
得到关键字后,就可以进行文档内容的关键字搜索进而得到匹配内容的文档了。
遍历文档,搜寻关键字匹配
| 文档编号 | 匹配关键字 | 匹配个数 |
|---|---|---|
| 1 | 年轻人、不讲武德、武德、耗子尾汁 | 4 |
| 2 | 年轻人、耗子尾汁 | 2 |
| 3 | 不讲武德、武德 | 2 |
| 4 | 我劝你 | 1 |
如上表所示,通过关键字的匹配,得出匹配个数。得到想要搜索的结果,相关度也是从文档1~4依次降序。
但是,细想上面搜索步骤,遍历文档,一个个文档内容进行关键字匹配,如果文档数量很多,内容巨大,假设网页的数量为N,那么关键字搜索的时间复杂度就为O(N),这样的搜索会有很大的效率问题。那么,怎么优化这个过程呢 ?
倒排
简单的说,用Value查询Key的过程,就是倒排索引
| 匹配关键字 | 文档ID |
|---|---|
| 年轻人 | 1,2 |
| 不讲武德 | 1,3 |
| 武德 | 1,3 |
| 我劝你 | 4 |
| 耗子尾汁 | 1,2 |
如上表所示,现在记录关键字与文档的一个映射关系,如关键字年轻人在文档1、文档2中出现。例如搜索的关键字是年轻人,则可从此记录中快速找到匹配关键字年轻人的文档为1和2,这样比遍历数据匹配内容要快得多。
安装
下面列出了各系统及插件的安装包链接,请自行下载安装,因为很多时候我们不仅仅要Elasticsearch还一些工具,这里建议使用Docker。
然后用docker-compose编排各容器
安装包及插件
Elasticsearch+Ik分词器 dockerfile
#ES+IK分词器
# Author: yiuman
FROM elasticsearch:7.10.0
MAINTAINER YiumanKam
ENV VERSION=7.10.0
ADD https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v${VERSION}/elasticsearch-analysis-ik-$VERSION.zip /tmp/
RUN /usr/share/elasticsearch/bin/elasticsearch-plugin install --batch file:///tmp/elasticsearch-analysis-ik-$VERSION.zip
RUN rm -rf /tmp/*
#打包运行 没墙的情况下 分词建议下载到本地 不然慢死你
#docker build -t es-ik:7.8.1 .
#docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" --name es-ik es-ik:7.8.1
Elasticsearch+Ik分词器+ElasticHD docker-compose编排
#构建ElasticSearch+IK分词+ ElasticHD
version: '3.3'
services:
elasticsearch:
# 没镜像的情况下使用
# build:
# context: ./
# dockerfile: Dockerfile
image: es-ik:7.10.0
container_name: elasticsearch
networks:
- net-es
#这里将elasticsearch的数据文件映射本地,以保证下次如果删除了容器还有数据
# volumes:
# - ../data/elasticsearch/data:/usr/share/elasticsearch/data
environment:
- discovery.type=single-node
ports:
- "9200:9200"
elastichd:
image: containerize/elastichd:latest
container_name: elasticsearch-hd
networks:
- net-es
ports:
- "9800:9800"
depends_on:
- "elasticsearch"
links:
- "elasticsearch:demo"
#这里要注意,es和eshd要在相同网络才能被links
networks:
net-es:
external: false
#运行
#docker-compose -f ./docker-compose-es-hd.yml up
如何使用?
下面Elasticsearch使用的过程都是基于JAVA版的REST API客户端进行的,而且不会进行细讲,若要比较深入的了解或使用其他方式进行调用请自行官网学习 文档地址
依赖
Maven
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.0</version>
</dependency>
Gradle
dependencies {
compile 'org.elasticsearch.client:elasticsearch-rest-high-level-client:7.10.0'
}
需要注意一下的是,公司的框架的jar中包含了低版本的lucene包,会有冲突需要排除。冲突JAR为lucene-analyzers-common-4.6.1.jar、lucene-core-4.6.1.jar
下面的例子简单的演示Rest客户端使用,具体细节官网都有,这里就不重复了,请认真看官网,认真看官网,认真看官网!!!
创建Rest客户端实例
Rest客户端分高级与低级两种,高级的是基于低级的搞的,一般情况下用高级的就好。
所有的操作都是基于Rest客户端实例进行调用的。
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.1.208", 9200, "http")));
关于索引的基本操作
创建索引
/**
* 最简单的方式
*/
//1.创建请求
CreateIndexRequest request = new CreateIndexRequest("sentiment");
//2.获取响应
//此处client是上面创建的高级Rest客户端实例
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
//3.关闭客户端
client.colse();
/**
* 创建索引自定义索引的相关信息
*/
//1.创建请求
CreateIndexRequest request = new CreateIndexRequest("sentiment");
//2.设置索引源信息
request.source("{\n" +
" \"settings\" : {\n" +
" \"number_of_shards\" : 1,\n" +
" \"number_of_replicas\" : 0\n" +
" },\n" +
" \"mappings\" : {\n" +
" \"properties\" : {\n" +
" \"title\" : { \"type\" : \"text\" },\n" +
" \"summary\" : { \"type\" : \"text\" },\n" +
" \"author\" : { \"type\" : \"text\" },\n" +
" \"publishTime\" : { \"type\" : \"date\" }\n" +
" }\n" +
" },\n" +
" \"aliases\" : {\n" +
" \"twitter_alias\" : {}\n" +
" }\n" +
"}", XContentType.JSON);
//3.获取响应
//此处client是上面创建的高级Rest客户端实例
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
client.colse();
查询索引
//获取名为sentiment的索引信息
GetIndexRequest indexRequest = new GetIndexRequest("sentiment");
GetIndexResponse getIndexResponse = client.indices().get(indexRequest, RequestOptions.DEFAULT);
//查看索引是否存在
GetIndexRequest request = new GetIndexRequest("sentiment");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
//查看索引的mapping(映射)信息
GetMappingsRequest getMappingsRequest = new GetMappingsRequest();
getMappingsRequest.indices("sentiment");
GetMappingsResponse mapping = client.indices().getMapping(getMappingsRequest, RequestOptions.DEFAULT);
//查询索引定义的字段的mapping信息
GetFieldMappingsRequest fieldMappingsRequest = new GetFieldMappingsRequest();
fieldMappingsRequest.indices("sentiment");
fieldMappingsRequest.fields("title", "summary", "author");
GetFieldMappingsResponse fieldMapping = client.indices().getFieldMapping(fieldMappingsRequest, RequestOptions.DEFAULT);
更新索引
//更新索引配置信息
UpdateSettingsRequest request = new UpdateSettingsRequest("sentiment");
//设置副分片的数量为0
Settings settings =
Settings.builder()
.put("index.number_of_replicas", 0)
.build();
request.settings(settings);
AcknowledgedResponse updateSettingsResponse =
client.indices().putSettings(request, RequestOptions.DEFAULT);
client.close();
删除索引
//删除指定名称的索引
DeleteIndexRequest request = new DeleteIndexRequest("sentiment");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
client.close();
关于IK分词器
ElasticSearch是有自己的分词器的,但是不满足我们的分词需求,所以使用大名鼎鼎的IK分词器插件对分词进行扩展
ik_max_word&ik_smart两个分析器的区别
- ik_max_word 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合
- ik_smart 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”
使用分词分析器
创建索引或更新索引的时候,定义相关属性,若需要使用分析器则声明,下面例子中JSON是上面创建索引的JSON扩展
{
"settings":{
"number_of_shards":1,
"number_of_replicas":0
},
"mappings":{
"properties":{
"title":{
"type":"text"
},
"summary":{
"type":"text"
},
"author":{
"type":"text"
},
"publishTime":{
"type":"date"
},
"content":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
关于文档的基本操作
创建文档
//创建文档对象(例如你的某个对象),这里用舆情类进行展示
Sentiment sentiment = new Sentiment();
sentiment.setId("1");
sentiment.setTitle("北京有一直猪乸生了20只猪崽,真牛逼~");
sentiment.setSummary("这只猪乸好犀利");
sentiment.setAuthor("小甘同学");
sentiment.setOrientation(Orientation.NEGATIVE);
sentiment.setPublishTime(new Date());
sentiment.setSourceType(SourceType.COMMENT);
sentiment.setSite("正盟");
sentiment.setUrl("http://www.baidu.com");
sentiment.setContent(null);
sentiment.setKeyWord("猪乸");
//指定文档的索引
IndexRequest indexRequest = new IndexRequest("sentiment");
//文档ID
indexRequest.id(sentiment.getId());
indexRequest.source(sentiment);
//请求创建文档
IndexResponse index = client.index(indexRequest, RequestOptions.DEFAULT);
client.close()
简单搜索
匹配+排序,这里需要注意下,如果使用了排序ES默认是不会算分数的,如果要算分数,则要加上”track_scores”:”true”
GET /sentiment/_search
{
"query": {
"term": {
"author": "小甘同学"
}
},
"track_scores":"true",
"sort": {
"id":{
"order":"desc"
}
}
}
//java
SearchRequest searchRequest = new SearchRequest("sentiment");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("author", "小甘同学"));
searchSourceBuilder.sort("id", SortOrder.DESC);
searchRequest.source(searchSourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
复合搜索
复合搜索有多种,分别为
- 布尔查询(bool query) 用于组合多个条件或复合句的默认查询
- 提高查询(boosting query)布尔查询会排除掉不匹配的文档,而提交查询则不会排除只会降下文档的匹配度
- 固定分数查询(constant_score query)指定固定的分数,一般都结合filter进行使用
- 最佳匹配查询(dis_max query)只会返回得分最大的文档
- 函数分数查询(function_score query)用于处理文档得分过程的查询
下面只对最常用的布尔查询进行讲解,其他的复合查询方式请阅读官网
布尔查询包含4中操作符,分别为
- must 必须匹配 ,会贡献分数
and - must_not 必须不匹配,不会贡献分数
not - should 选择性匹配,至少满足一条 ,贡献分数
or - filter 过滤子句,必须匹配,不贡献分数
常用的条件操作符有
- term 精确查询
= - match 匹配查询
like支持全文检索及分词器 - range 范围查询
gt、gte、lt、lte
例子:查询作者为小甘同学,关键字为猪乸且发布时间大于等于2020-10-10的数据
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "authoer" : "小甘同学" }
},
"filter": {
"term" : { "keyword" : "猪乸" }
},
"must_not" : {
"range" : {
"publishTime" : { "gte" : "2020-10-10" }
}
}
}
}
}
//java
SearchRequest searchRequest = new SearchRequest("sentiment");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.termsQuery("author","”小甘同学"));
boolQueryBuilder.filter(QueryBuilders.termsQuery("keyword","猪乸"));
boolQueryBuilder.must_not(QueryBuilders.rangeQuery("publishTime","2020-10-10"));
searchRequest.source(boolQueryBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
分页查询
Elasticsearch中的对与数据量较小的分页很简单,只要在查询中添加分页条件(
form,size)则可
- 简单分页
GET /_search
{
"from": 5,
"size": 20,
"query": {
"match": {
"author": "小甘同学"
}
}
}
SearchRequest searchRequest = new SearchRequest("sentiment");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("author", "小甘同学"));
searchSourceBuilder.from(5)
searchSourceBuilder.size(20)
searchRequest.source(searchSourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
当查询匹配的数据量大的时候,使用分页条件则会失效,Elasticsearch的最大数据量是10000,这种时候就要使用
scrollId深度分页(游标分页)或者search_after深度分页进行处理
因为游标分页会缓存数据到内存,若使用不当或者清理不及时会引发内存问题,So,一般用户搜索,比较频繁的查询的情况下建议使用search_after分页处理,下面也只对search_after的使用进行说明 。
注意,使用search_after分页的时候最好添加排序字段,防止分页出现问题
Search_after的使用方式其实就是将上一次查出来的数据最后一条数据的排序值添加到下一次查询中去使用。
//第一次请求
GET /sentiment/_search
{
"size": 5,
"query": {
"match": {
"author": "云浮"
}
},
"sort": {
"id": "asc",
"publishTime": "desc"
}
}
//第一次请求返回数据
{
...
"hits":[
...
{
....,
"sortValues":["1f46c01879746f8c7e215a1ff064734d"]
}
]
}
//第二次请求
GET /sentiment/_search
{
"size": 5,
"query": {
"match": {
"author": "云浮"
}
},
"sort": {
"id": "asc",
"publishTime": "desc"
},
"search_after":["1f46c01879746f8c7e215a1ff064734d"]
}
//java
//第一次请求
SearchRequest searchRequest1 = new SearchRequest("sentiment");
SearchSourceBuilder searchSourceBuilder1 = new SearchSourceBuilder();
searchSourceBuilder1.query(QueryBuilders.matchQuery("author", "云浮"));
searchSourceBuilder1.sort("id");
searchSourceBuilder1.size(10);
SearchResponse searchResponse1 = client.search(searchRequest1, RequestOptions.DEFAULT);
//第二次请求
SearchRequest searchRequest2 = new SearchRequest("sentiment");
SearchSourceBuilder searchSourceBuilder2 = new SearchSourceBuilder();
searchSourceBuilder2.query(QueryBuilders.matchQuery("author", "云浮"));
searchSourceBuilder2.sort("id");
//这里添加searchAfter参数
searchSourceBuilder2.searchAfter(searchResponse1.getHits().getHits()[9].getSortValues());
searchSourceBuilder2.size(10);
SearchResponse searchResponse2 = client.search(searchRequest2, RequestOptions.DEFAULT);
遇到的问题
- 创建索引的时候不声明mapping信息,保存文档的时候ES会自动根据文档字段信息去构建mapping,会将大部分字段定义为type=”text”的类型,而text类型字段是不支持排序的!!!
- 解决:创建索引的时候尽量自定义mapping信息,至少将主键设置为keyword或number类型数据,让查询至少有排序可用
写在最后
网上的博客资料不知道什么时候发布的,可能不是最新的,可能有部分的东西已经过时,如果是最新版本的可以稍微参考下,但是最好还是看官网学习。

